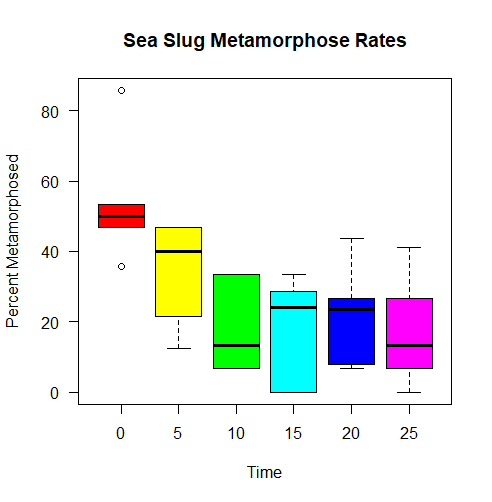
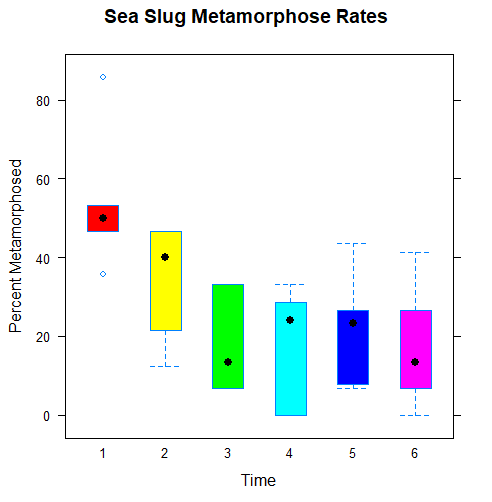
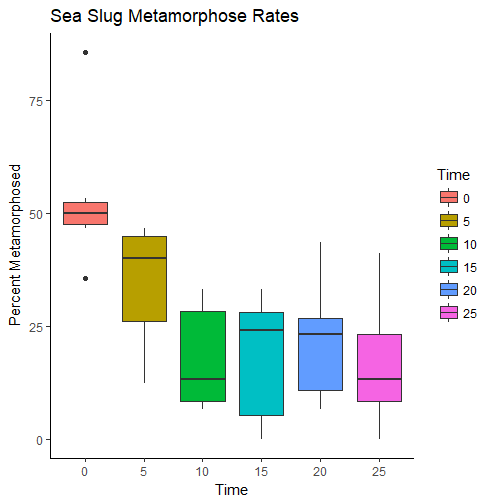
The assignment this week was to create two matrices and calculate their inverses and their determinants. The values given were:
A=matrix(1:100, nrow=6)
B=matrix(1:1000, nrow=6)
Unfortunately, those values don’t work – a matrix has to have a number of values that can be translated into a matrix given the number of rows, and you can’t divide 6 evenly into either 100 or 1000. To remedy this, I changed the number of rows for each matrix from 6 to 10.
The R commands I used were:
A <- matrix(1:100, nrow=10)
B <- matrix(1:1000, nrow=10)
The R command to find the inverse is solve(), so next I ran that command on the two matrices.
And…that didn’t work out so well. The error message told me that A was singular, so it didn’t have an inverse. And B wasn’t square, so it couldn’t have an inverse either.
The determinant is found with the det() function, so I tried that out too. The determinant of A was 0 (makes sense, given the result I got trying to get the inverse), and then B threw an error because it couldn’t get the determinant of a matrix that wasn’t square. Foiled again.
So I dug into random numbers to generate a non-sequential set of numbers for a new matrix. And I wanted the result to be repeatable (to make it easier to replicate and grade), so I used set.seed() and runif(). I also focused only on A, because I couldn’t make a square matrix out of 1000 numbers. Sorry, B.
set.seed(123)
A <- matrix(runif(100, min=1, max=100), nrow=10)
That made A into:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 29.470174 95.726501 89.06439 96.339399 15.13720 5.537286 66.84640 75.693041 25.11833 13.93887
[2,] 79.042208 45.880081 69.58754 90.327605 42.04009 44.777807 10.38923 63.292892 67.13750 65.65709
[3,] 41.488715 68.079493 64.41017 69.379823 41.95871 80.093560 39.01299 71.308058 42.34703 35.00813
[4,] 88.418723 57.690707 99.43271 79.751274 37.51570 13.068027 28.16398 1.061853 79.03139 66.01905
[5,] 94.106261 11.189544 65.91487 3.436755 16.09203 56.533850 81.64936 48.056341 11.18360 32.71695
[6,] 5.510093 90.082672 71.14452 48.301801 14.74180 21.446608 45.40312 22.791770 44.05438 19.58142
[7,] 53.282443 25.362686 54.86254 76.087494 24.07038 13.625633 81.19637 38.601837 98.51074 78.44714
[8,] 89.349485 5.163894 59.82006 22.424386 47.13028 75.577479 81.42656 61.664329 89.41206 10.26590
[9,] 55.592066 33.464151 29.62681 32.499920 27.33129 89.609491 79.63989 35.827993 88.76044 47.21113
[10,] 46.204859 95.495861 15.56425 23.930953 85.92494 38.071815 44.54334 12.002407 18.33021 51.63904
Now I could get the inverse and determinant:
solve(A)
det(A)
The determinant was returned as 2.471786e+18. The inverse was:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0.012404331 0.014655568 -0.024950989 0.002363324 0.0024883203 -0.007528454 -0.0155334345 -0.0006610557 0.016073655 0.0022233330
[2,] 0.005498005 0.018905283 -0.025300934 -0.008300409 0.0010619645 0.014340780 -0.0126398624 -0.0031970118 0.012703786 0.0043549557
[3,] -0.013711628 -0.010417761 0.019364467 0.004667232 0.0055394390 0.012004889 0.0086199292 0.0039862656 -0.020829129 -0.0050540560
[4,] 0.016471142 -0.022182260 0.020340061 0.019413907 -0.0105374733 -0.033021567 -0.0004251472 -0.0056725764 0.009574390 -0.0026334849
[5,] -0.007553095 -0.017673061 0.024248454 0.005571115 -0.0059687886 -0.008097359 0.0116419862 0.0105975716 -0.021416142 0.0075871860
[6,] -0.002072423 -0.011888989 0.018786337 0.007942099 -0.0007145655 -0.008617087 -0.0040702093 -0.0047360911 0.007951269 -0.0036383211
[7,] 0.006674229 -0.018906014 0.008345737 0.005219274 0.0007914594 -0.011320821 0.0069961331 -0.0008031338 0.002070228 0.0013363260
[8,] -0.003758705 0.025465328 -0.015070004 -0.022802631 0.0051107692 0.017684411 0.0024590013 0.0049765108 -0.008003417 0.0006537543
[9,] -0.003791975 0.014823496 -0.017791253 -0.007537918 -0.0051919999 0.015235601 -0.0016023448 0.0075767455 0.003805645 -0.0011647558
[10,] -0.014208379 0.008644982 0.002271745 -0.008820289 0.0094544005 0.011974071 0.0124641286 -0.0093644472 -0.007537431 0.0012324687
The code for my program is here:
https://github.com/jered0/lis4930-rpackage/blob/master/module5/matrixinverse.r